
无约束问题¶
约 8457 个字 14 行代码 3 张图片 预计阅读时间 28 分钟
| 内容 | 重要性 | 描述和注 |
|---|---|---|
| 凸规划概念以及性质 | ⭐⭐⭐ | 主要掌握局部极值为全局极值 |
| Fibonacci法和0.618法 | ⭐⭐⭐⭐ | 只需要掌握算法步骤应该就可以了 |
| 一维搜索 | ⭐⭐⭐⭐ | Armijo准则和Zoutendijk定理 |
| 最速下降法 | ⭐⭐⭐⭐⭐ | 相当重要的算法,机器学习的灵魂 |
| 共轭梯度法 | ⭐⭐⭐⭐⭐ | 思路很巧妙,除算法外还可以思考证明 |
| 拟牛顿法 | ⭐⭐⭐⭐⭐ | 掌握DFP,BFGS方法即可 |
基本概念¶
非线性规划问题的数学模型(同理线性规划,只是函数不再要求线性)
极值问题¶
- 局部极值和全局极值
- 极值点存在的条件
- 必要条件:梯度为0
- 充分条件:梯度为0且Hesse矩阵是半正定(半负定)
- 凸函数和凹函数(定义和性质)
- 凸函数的性质
- 函数凸性的判定
- 凸函数的极值(极小值就是最小值)
- 凸函数的任一极小点就是它在\(R\)上的最小点,而且极小点集为凸集
- 可微的凸函数,如果\(\exists X^{*}\in R,\forall X\in R,\nabla f(X^{*})^{T}(X-X^{*})\geqslant 0\),则\(X^{*}\)是\(f(X)\)在\(R\)上的最小点
对于第三点中的性质与判定总结如下:
凸函数简单性质
- \(f(x)\)为定义在凸集\(R\)上的凸函数,则对于任意\(\beta\in R>0\),函数\(\beta f(x)\)也是定义在\(R\)上的凸函数
- \(f_{1},f_{2}\)为定义在凸集\(R\)上的凸函数,则\(f=f_{1}+f_{2}\)也是定义在\(R\)上的凸函数
- \(f(x)\)为定义在凸集\(R\)上的凸函数,则对于任意\(\beta\in R\),集合\(S_{\beta}\left\{ X|X\in R,f(X)\leqslant \beta \right\}\)是凸集(\(S_{\beta}\)称为水平集)
函数凸性的判定
显然可以利用定义直接判定,对于可微的凸函数也可以使用下面两个判定定理
- 一阶条件 \(R\)为\(E^{n}\)上开凸集,\(f(X)\)在\(R\)上具有一阶连续偏导数,则\(f(X)\)为\(R\)上凸函数的充要条件是对任意\(X^{(1)},X^{(2)}\in R\),恒有\(f(X^{(2)})\geqslant f(X^{(1)})+\nabla f(X^{(1)})^{T}(X^{(2)}-X^{(1)})\)
- 二阶条件 \(R\)为\(E^{n}\)上开凸集,\(f(X)\)在\(R\)上具有二阶连续偏导数,则\(f(X)\)为\(R\)上凸函数的充要条件是\(f(X)\)的Hessian矩阵\(H(X)\)在\(R\)上处处半正定
凸函数的定义实际上是说凸函数两点间的线性插值不低于这个函数的值,而判定定理1则是说,基于某个点导数的线性近似不高于这个函数的值(几何意义的理解方式)
可以证明若凸规划的可行域是凸集,局部最优解也是全局最优解,而且最优解的集合形成一个凸集,那么凸规划的目标函数为严格凸函数时,其最优解必定唯一(这一找到局部最优也就是全局最优)
Theorem
若\(f(X)\)是定义在凸集上的可微凸函数,若存在\(X^{*}\in R\),使得对于所有的\(X\in R\)有\(\nabla f(X^{*})(X-X^{*})\geqslant 0\),则\(X^{*}\)为\(f(X)\)在\(R\)上的最小点(全局极小值)
凸规划(convex planning)¶
Claim
凸的就是好的!
凸规划是一类简单而又有重要意义的非线性规划(线性规划也是凸规划)
下降迭代算法¶
为了求某可微函数的最优解可以先使该函数的梯度为0,求得平稳点然后利用充分条件进行判定,对于简单函数这种方法是可行的,对于比较复杂的函数则不容易求解非线性方程组,可以直接使用迭代法.
迭代法的基本思想是按照某种规划或算法找出比原解更好的解,得到一个序列然后用柯西收敛准则进行判定,由于计算机只能有限迭代所以达到一定精度后即可停止(注意算法需要给出一个初始估计值\(X^{(0)}\)).
一些基本定义
搜索方向:能够沿该方向使目标函数值有所下降
步长(步长因子):沿着搜索方向移动的距离
下降迭代算法的步骤:
- 选定初始点
- 确定搜索方向(最关键的一步)
- 从初始点出发沿方向求步长产生下一个迭代点
- 检查得到的新点是否为极小点或近似极小点
注:各种算法的区分,主要是在于确定搜索方向的方法不同
确定步长的方法:
- 常数方法:定义为常数,无法保证目标函数值下降
- 可接受点算法:只要能使目标函数下降就可以任意选取步长
- 基于沿搜索方向使目标函数值下降最多,这一过程称为一维搜索或线搜索,确定的步长为最佳步长
一维搜索的一个重要的性质就是:在搜索方向上所得最优点处的梯度和该搜索方向正交,归纳为下面的定理
Theorem 7
设\(f(X)\)有一阶连续偏导数,\(X^{(k+1)}\)按下列规则迭代:
\(\lambda_{k}:\min f(X^{(k)}+\lambda P^{(k)}),X^{(k+1)}=X^{(k)}+\lambda_{k}P^{(k)}\)
则有\(\nabla f(X^{(k+1)})^{T}P^{(k)}=0\)
Proof.
简单证明一下,构造函数\(\phi(\lambda)=f(X^{(k)}+\lambda P^{(k)})\),那么有\(\phi'(\lambda_{k})=0\)(一阶条件),代入函数为\(\nabla f(X^{(k)}+\lambda_{k}P^{(k)})^{T}P^{(k)}=\nabla f(X^{(k+1)})^{T}P^{(k)}=0\)
下面讨论算法的收敛速度
若是序列\(\left\{ X^{(k)} \right\}\)收敛于\(X^{*}\),存在与迭代次数无关的数\(0<\beta<\infty\)和\(\alpha \geqslant 1\),使得K从某个\(k_{0}>0\)开始,都有
就称\(\left\{ X^{(k)} \right\}\)收敛的阶为\(\alpha\),或是\(\alpha\)阶收敛
- \(\alpha=2\)称为二阶收敛,也可说具有二阶敛速
- \(\alpha>1\)称为超线性收敛
- \(\alpha=1\),且\(0<\beta<1\)称线性收敛或一阶收敛
- \(\alpha=1,\beta=1\)称为次线性收敛
注:就是一些概念而已,类似Lipschitz条件
还需要决定什么时候停止计算
常用的终止计算准则(\(\varepsilon_{i}\)为事先给定的足够小的正数):
- 根据相继两次迭代的绝对误差:\(\lvert X^{(k+1)}-X^{(k)} \rvert<\varepsilon_{1}\)
- 根据相继两次迭代的相对误差:\(\frac{\lvert X^{(k+1)}-X^{(k)} \rvert}{\lvert X^{(k)} \rvert}< \varepsilon_{3}\),这时要求分母不接近于0
- 根据目标函数梯度的模足够小:\(\lvert \nabla f(X^{(k)}) \rvert<\varepsilon_{5}\)
一维搜索¶
常用的一维搜索方法
- 试探法("斐波那契法",0.618法)
- 插值法(抛物线插值法,三次插值法)
- 微积分中的求根法(切线法,二分法)
注:以下的两种方法Fibonacci法和0.618法都需要在单峰函数的条件下使用否则可能会收敛到错误的位置(错误收敛).
补充单峰函数的定义(这在图形上是显然的):
单峰函数
\(f\)是定义在\(\left[ a,b \right]\)上的一元实函数,\(\overline{x}\)是\(f\)在\(\left[ a,b \right]\)上的极小点,并且对任意的\(x^{(1)},x^{(2)}\in \left[ a,b \right],x^{(1)}<x^{(2)}\),有\(x^{(2)}\leqslant \overline{x},f(x^{(1)})>f(x^{(2)})\),\(x^{(1)}\geqslant \overline{x},f(x^{(1)})<f(x^{(2)})\)
Fibonacci法¶
算法原理(考虑单峰函数):
- 内部取两个点划分区间
- 判断两点函数值大小重新确认区间
- 继续搜索
实际就是通过不断缩短区间长度达到即使在区间内反复摆动也可以达到比较好的近似极值点的效果
缩短率与计算次数的关系
计算函数值\(n\)次,能把包含极小点的区间缩小到什么程度?计算\(n\)次可以把原本多大的区间缩小为一个单位长度的区间.
这种方法迭代n次的缩短率符合Fibonacci数列的值记第n次迭代值为\(F_{n}\)
那么如果要使迭代n次后的长度缩短为原本长度的\(\delta\)倍(中文上语病忽略),只需要保证\(F_{n}\geqslant \frac{1}{\delta}\)
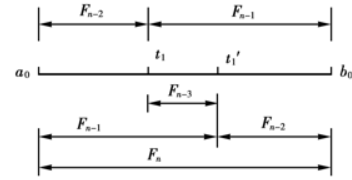
缩短区间的步骤:
- 确定试点的个数\(n\),简单根据Fabonacci数列的值即可得到
- 选取前两个试点的位置
- \(t_{1}=a_{0}+ \frac{F_{n-2}}{F_{n}}(b_{1}-a_{1})=b_{0}+\frac{F_{n-1}}{F_{n}}(a_{0}-b_{0})\)
- \(t_{1}'=a_{0}+ \frac{F_{n-1}}{F_{n}}(b_{0}-a_{0})\)
- 计算两个函数值比较大小
- 计算新的点函数值然后迭代
可以画一个简单的图表示点的复用关系
0.618法(黄金分割法)¶
实际上就是Fibonacci方法的比值求极限得到黄金分割比,然后利用黄金分割点的内生性就可以增加选取点和分割区间的效率(数学文化的含金量还在上升)
不管是黄金分割法还是Fibonacci法,选取的点基本都被复用过,这样就提高了效率减少了成本:不要浪费!
其他的一些方法:
- 二分法
- 牛顿法
- 在极小点附近用二阶泰勒展开逼近得到估计
- 一直利用切线迭代即可
- 割线法
- 抛物线法
- 两点三次插值法
信息和算法
已知信息的多少会决定算法的复杂度和算法效率,所以笔者想到了一些优化方向:
- 少信息如何达到基本的精度和效率?
- 多信息怎么达到最高的效率?
牛顿法¶
基本思想:在极小点附近用二阶Talor多项式近似目标函数\(f(x)\),进而求出极小点的估计值
令
求导得
牛顿法(算法步骤)
(1) 给定初点\(x^{(0)}\),允许误差\(\varepsilon>0,k=0\)
(2) 若\(\lvert f'(x^{(k)}) \rvert<\varepsilon\),则停止迭代,得到\(x^{(k)}\)
(3) 计算点\(x^{(k+1)}\)
牛顿法的收敛速度和收敛性受初始点选择的影响较大,如果初始点选择的很接近目标函数极小值点那么收敛的会很快,反之不一定收敛
割线法¶
如图所示:
def secant_method(f, x0, x1, iterations):
"""Return the root calculated using the secant method."""
for i in range(iterations):
x2 = x1 - f(x1) * (x1 - x0) / float(f(x1) - f(x0))
x0, x1 = x1, x2
# Apply a stopping criterion here (see below)
return x2
def f_example(x):
return x ** 2 - 612
root = secant_method(f_example, 10, 30, 5)
print(f"Root: {root}") # Root: 24.738633748750722
相比于牛顿法来说收敛速度比较慢,但是不需要计算二阶导数,缺点就是和牛顿法一样也不具有全局收敛性,如果初始点选择的不好可能不收敛
抛物线法¶
基本思想是在极小点附近用二次三项式\(\phi(x)\)逼近目标函数\(f(x)\),令\(\phi(x),f(x)\)在三个点处具有相同的函数值并且还具有以下关系:
那么为了求\(\phi(x)\)的极小点,令\(\phi'(x)=b+2cx=0,x= - \frac{b}{2c}\)
插值法的原理比较多,也比较复杂但是并不是很难可以自己参考资料(可以参考JLU的一本数值分析初步)
以下是补充的内容,考试不做要求
\(\alpha_{k}\)的选取¶
精确线搜索算法¶
首先构造一元辅助函数(\(d^{k}\)是给定的下降方向)
线搜索的目标是选取合适的步长使得\(\phi(\alpha_{k})\)尽可能减小,也就是
- \(\alpha _k\)应该使得\(f\)充分下降
- 不应在寻找\(\alpha_{k}\)上花费过多的计算量(由于这一点精确线搜索实际使用较少)
自然的想法就是寻找\(\alpha_{k}\),使得\(\alpha_{k}=arg\min\limits_{\alpha>0}\phi(\alpha)\)
那么这就是解析的最佳的步长,这种线搜索算法就称为精确线搜索算法
非精确线搜索算法¶
如果不要求最小仅要求满足某些不等式约束条件,这种线搜索方法就称为非精确线搜索算法,选取\(\alpha_{k}\)需要满足的要求被称为线搜索准则,线搜索准则的合适与否直接决定了算法的收敛性。
- Armijo准则
- Goldstein准则
- Wolfe准则
- Zoutendijk定理
为了保证每一步的迭代充分下降引入下面的Armijo准则,这也是最基本的一个准则.
Armijo准则
设\(d^{k}\)是点\(x^{k}\)的下降方向,若
则称步长\(\alpha\)满足Armoji准则,其中\(c_{1}\in(0,1)\)是一个常数
为了克服Armijo准则的缺陷需要引入其他准则保证每一步的\(\alpha^{k}\)不会太小,并且需要配合其他准则保证迭代的收敛性,因为\(\alpha=0\)显然是满足条件的,但是此时迭代点不变
回退法
给定初值后,通过不断以指数方式缩小试探步长,找出第一个满足Armijo准则的点,回退法选取\(\alpha_{k}=\gamma^{j_{0}} \hat{\alpha}\)
这种算法称为回退法是因为它的实验值由大至小,保证输出的\(\alpha_{k}\)尽可能的大,并且由于下降方向是给定的,当\(\alpha\)充分小时一定会满足Armijo准则,也就确保了算法一定会终止
实际应用中也会给\(\alpha\)设定一个下界,防止步长过小
Armoji准则只要求\(\left( \alpha,\phi(\alpha) \right)\)必须处在某直线下方,我们也可使用相同的形式使得该点必须处在另一条直线的上方,这就是Armijo-Goldstein准则(Goldstein准则)
Goldstein准则
设\(d^{k}\)是点\(x^{k}\)的下降方向,若
则称步长\(\alpha\)满足Goldstein准则,其中\(c\in\left( 0, \frac{1}{2} \right)\)是一个常数
Goldstein准则也有直观的几何含义,指的是\(\left( \alpha,\phi(\alpha) \right)\)必须在两条直线之间,这种做法就可以去掉一些过小的\(\alpha\)
需要指出Goldstein准则能够使得函数值充分下降但是也可能避开了最优的函数值(考虑单峰函数即可举出例子),这引导我们给出新的Wolfe准则:
- 第一条就是Armijo准则
- 第二个不等式是Wolfe准则的本质要求,也称为曲率条件(实际上就是\(\phi'(\alpha)\geqslant c_{2}\phi'(0)\)),这保证步长不会过小,因为原本的导数希望是负数(选取的是下降方向,想想下降方向的定义呢),所以为了逼近0就可以进行放大。实际上这种做法可以改进,使得斜率必须增大的同时,也使得无法增加的特别大(可能使得步长过于宽松导致错过最优解,保证收敛的平稳性),因此还有加强版本的Wolfe准则曲率条件:\(\lvert \phi'(\alpha) \rvert \leqslant c_{2}\lvert \phi'(0) \rvert)\)
这个部分知乎有一篇笔记我认为写的很清楚
Wolfe准则
设\(d^{k}\)是点\(x^{k}\)的下降方向,若
则称步长\(\alpha\)满足Wolfe准则,其中\(c_{1},c_{2}\in\left( 0, 1\right)\)是常数且\(c_{1}<c_{2}\)
由于极小值点满足Wolfe准则,永远满足条件2,而选择较小的\(c_{1}\)可以使得满足条件1,那么在大多数情况下使用Wolfe准则会包含线搜索子问题的精确解
这里的Wolfe条件包含有强Wolfe条件和弱Wolfe条件
Zoutendijk定理
考虑一般的迭代格式:\(x^{k+1}=x^{k}+\alpha_{k}d^{k}\),其中\(d^{k}\)是搜索方向,\(\alpha_{k}\)是步长,而且满足Wolfe准则,假设目标函数下有界,连续可微并且梯度满足Lipschitz连续:\(\lVert \nabla f(x)-\nabla f(y) \rVert\leqslant L\lVert x-y \rVert,\forall x,y\in \mathbb{R}^{n}\)
那么
其中\(\cos\theta_{k}\)是负梯度\(-\nabla f(x^{k})\)和下降方向\(d^{k}\)夹角的余弦,即
这个不等式也被称为Zoutendijk条件
注1:根据Zoutendijk条件即可得到成立时应当有\(\lim\limits_{ k\to \infty }\nabla f(x^{k})=0\),线搜索算法收敛性建立在Zoutendijk条件之上,本质要求是下降方向与负梯度方向不趋于正交,几何直观上就是如果趋于正交Tarlor展开后函数值几乎不变,所以要求\(d^{k}\)与梯度正交方向夹角有一致下界
注2: 该部分主要注意Armijo准则和Zoutendijk条件即可
注3:对于收敛性算法和收敛性分析其实是笔者比较感兴趣的问题,希望有机会能再补充一门数值计算课(可能会选计算数学那边的课或者自己看书),并且渐进理论也是统计上很重要的一个方向.
无约束极值问题的解法¶
本节研究无约束极值问题
求解上述问题常使用迭代法,可分为两类
- 利用函数的一阶或二阶导数,用到了函数的解析性质,称为解析法
- 仅用到函数值不用到解析性质那么称为直接法
本章介绍几种常用的基本方法,前三种为解析法,后一种属于直接法
参考资料:
1. 机器学习之数学(博客园)
2. 最速下降法的简洁原理介绍
梯度法(最速下降法)¶
梯度法的基本原理¶
梯度下降法(Gradient descent),顾名思义,就是自变量沿着梯度向量的反方向进行移动,因为梯度的方向是上升的方向,负梯度方向就是下降最快的方向.
通过在负梯度方向的一维搜索,来确定使\(f(X)\)最小的\(\lambda_{k}\),这种梯度法就是所谓的最速下降法。
下面给出计算步骤:
计算步骤¶
- 给定初始近似点和精度要求,如果精度满足,即为近似极小点
- 若是不满足,求步长,计算下个迭代点,求步长的方法可用精确线搜索(最佳步长),或非精确线搜索
- 一般的,如此迭代直到找到符合条件的近似解
若是\(f(X)\)具有二阶连续偏导数,那么在\(X^{(k)}\)作泰勒展开就可以近似:
那么可以对\(\lambda\)求导使得等于0,得到近似的最佳步长
最速下降法算法¶
最速下降法(Steepest descent)是梯度下降法的一种更具体实现形式,其理念为在每次迭代中选择合适的步长\(\alpha_{k}\),使得目标函数值能够得到最大程度的减少。
每一次迭代都在梯度的反方向,我们总可以找到一个新的点使得在这个方向上达到最小值,也就是方向与步长都达到最优(局部上).
注:每次迭代的路径与上一次垂直,并且如果梯度不等于0下一次迭代必定下降
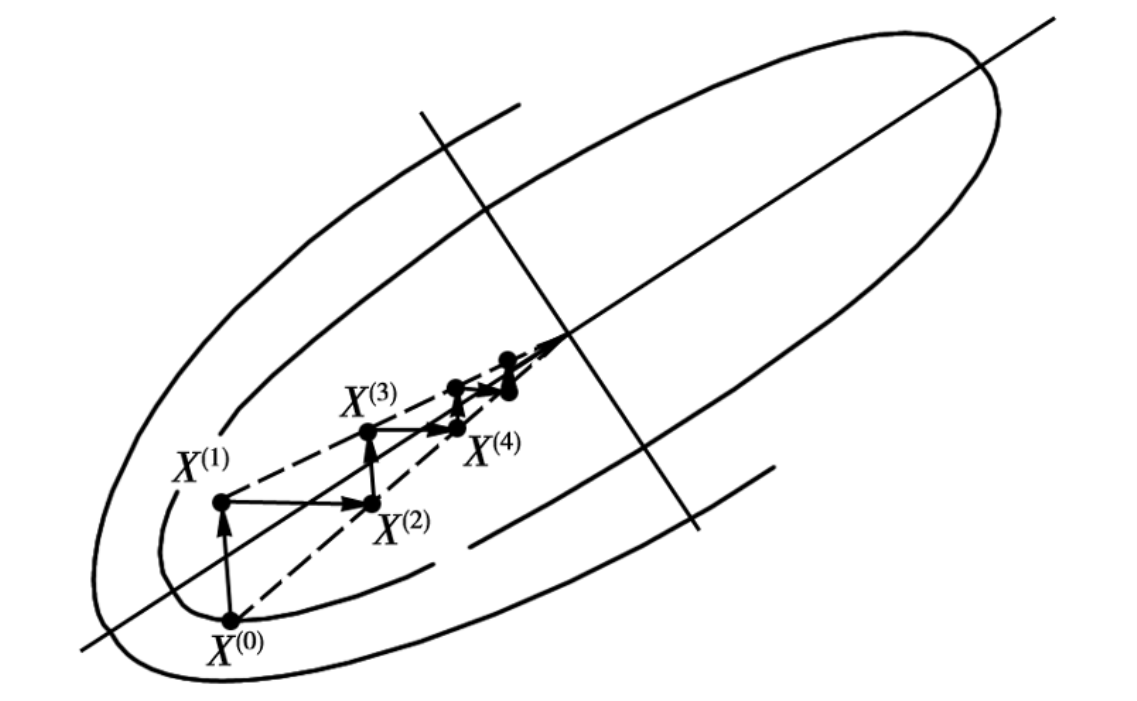
最速下降法(算法)
Step 1 给出\(x_{1}\in \mathbb{R}^{n},0\leqslant \varepsilon \ll 1,k:=1\)
Step 2 \(d_{k}=-\nabla f(x_{k}),\lVert d_{k} \rVert_{2}\leqslant \varepsilon\)停止
Step 3 利用精确线搜索\(\alpha_{k}>0\),\(f(x_{k}+\alpha_{k}d_{k})=\min\limits_{\alpha>0}f(x_{k}+\alpha d_{k})\)
Step 4 \(x_{k+1}=x_{k}+\alpha_{k} d_{k},k:=k+1\),回到2
注:\(\alpha_{k}\)为步长,在深度学习中被称为学习率(learning rate),控制了梯度下降速度的快慢.
理解一个算法最好还是依靠例子进行实操:
使用梯度法
求\(f(X)=(x_{1}-1)^{2}+(x_{2}-1)^{2}\)的极小点,\(\varepsilon=0.1\)
Sol.
取初始点\(X^{(0)}=(0,0)^{T}\)
那么\(\nabla f(X)=\left[ 2(x_{1}-1),2(x_{2}-1) \right]^{T}\),\(\nabla f(X^{(0)})=(-2,-2)^{T}\)
还有\(\lVert \nabla f(X^{(0)}) \rVert^{2}=\left( \sqrt{ (-2)^{2}+(-2)^{2} } \right)^{2}=8>\varepsilon\)
求解完毕
需要注意的是如果确定了步长,那么不一定收敛,迭代点可能会出现来回震荡的问题,所以必须不断减少步长的值
注1:由于负梯度方向的最速下降性,容易被误以为负梯度方向是理想的搜索方向,但是实际上\(X\)点处的负梯度方向在局部上才具有那种最速下降的性质,如果在全局上(对于整个极小化过程来说)则不一定.
注2:有时用最速下降法趋近极小点时,其搜索路径呈直角锯齿状,在开头几步,目标函数值下降较快,但接近极小点\(X^{*}\)时,收敛速度就不理想了.特别是当目标函数的等值线椭圆比较扁平时,收敛速度就更慢了.因此,在实用中,常将梯度法和其他方法联合起来应用,在前期使用梯度法,而在接近极小点时,则使用收敛较快的其他方法.
注3:机器学习中的梯度下降法,梯度下降法和反向传播算法是深度学习的基石,我们用梯度下降法更新神经网络的参数,用反向传播算法一层一层地将误差由后向前传播
共轭梯度法(Conjugate gradient method)¶
参考资料
下面给出一些基本的定义:
共轭方向¶
\(X,Y\)是\(\mathbb{R}^{n}\)中的两个向量,若有\(X^{T}Y=0\),就称\(X,Y\)正交
推广正交到共轭,再设\(A\)为\(n\times n\)的正定阵,那么如果\(X,AY\)正交有
则称\(X,Y\)关于\(A\)共轭.
注:如果\(A=I\),则上述条件即为通常的正交.
下面是共轭的一个小的性质:
定理(共轭独立)
\(A\)为\(n\times n\)正定阵,\(P^{1},P^{2},\dots,P^{n}\)为\(A\)共轭的非零向量,那么这组向量线性无关
Proof.
按照定义写出线性表达式,然后利用共轭乘上其中任意一个向量与\(A\)的乘积,\(\left( P^{i} \right)^{T}A\),根据共轭可知\(\alpha_{i}=0\),循环使用得线性无关.
考虑无约束极值问题的一个特殊情形:
其中A为对称正定阵,\(X,B\in E^{n},c\in \mathbb{R}\)
上面的问题也被称为正定二次函数极小问题,在整个最优化问题中起着极其重要的作用
对于这个问题有一个很有用的定理
二次终止定理
设向量\(P_{i},i=0,\dots,n-1\)为A的共轭,从任一点\(X^{(0)}\)出发分别以\(P^{(0)},P^{(1)},\dots,P^{(n-1)}\)为搜索方向的算法,经过n次一维搜索收敛于问题的极小点
Proof.
\(\nabla f(X)=AX+B\),设每次搜索后得到的近似解为\(X^{(1)},\dots,X^{(n)}\),相继代入算法方程可知:
由于一维搜索时为了确定最佳步长有\(\nabla f(X^{(k+1)})P^{(k)}=0\)
从而可知\(\nabla f(X^{(n)})=0\)
十分巧妙的利用最优步长的方程式代入化简递推式
注:任一初始点的条件十分强大,因为推导过程中由于共轭的性质将所有的项全部归为0了,收敛速度与初始点无关,并且一定会收敛!
正定二次函数的共轭梯度法¶
由于\(A\)对称正定阵,存在唯一极小点,若是已知某共轭向量组可以利用上述定理求得极小点,这就是共轭梯度法
下面开始详细解释共轭梯度法的过程和公式推导的过程:
注:一个重要的迭代条件是\(\nabla f(X)=AX+B\implies\)
但是\(X^{(k+1)}=X^{(k)}+\lambda_{k}P^{(k)}\implies \nabla f(X^{(k+1)})-\nabla f(X^{(k)})=\lambda_{k}AP^{(k)}\)
- 任取初始近似点,并以该点的负梯度方向为搜索方向也就是\(P^{(0)}=-\nabla f(X^{(0)})\)
- 进行一维搜索,沿着\(X^{(0)}+\lambda P^{(0)}\),算出\(\nabla f(X^{(1)})\),根据原本的共轭性质得到\(\nabla f(X^{(1)})^{T}P^{(0)}=-\nabla f(X^{(1)})^{T}\nabla f(X^{(0)})=0\),从而可知正交
- 不同迭代点的梯度构成正交系,于是可以在它们生成的二维子空间内寻找\(P^{(1)}=-\nabla f(X^{(1)})+\alpha_{0}\nabla f(X^{(0)})\)
注:为了满足正交的条件也就是需要满足方程组:
方便起见令\(\beta_{0}=-\alpha_{0}= \frac{\nabla f(X^{(1)})^{T}\nabla f(X^{(1)})}{\nabla f(X^{(0)})^{T}\nabla f(X^{(0)})}\)
- 下面的过程类似,同样是正交系,在子空间内找下一个共轭的向量,然后继续推导迭代点的梯度
一直迭代就可以得到一般的共轭梯度法计算公式:
计算步骤¶
- 选择初始近似,给出允许误差
- 计算共轭向量,导出下一个迭代点,计算步长可以使用一维搜索法
- 继续迭代下一个近似点
- 若是梯度模平方小于允许误差就停止,否则回到3
注:理论上二次函数只要迭代n次一定可以找到极小点,但是实际计算中由于数据的舍入和计算误差积累往往不能达到,但是维数最大到n继续迭代没有意义,那么就应当以\(X^{(n)}\)作为新的初始近似,重新开始迭代.
理论总是比较枯燥的,下面给出一个实例:
试用共轭梯度法求下述二次函数的极小点
Sol.
化为\(f(X)= \frac{1}{2}X^{T}AX+B^{T}X+c\)的形式:
\(X^{(0)}=(-2,4)^{T},\nabla f(X)=\left[ (3x_{1}-x_{2}-2),(x_{2}-x_{1}) \right]^{T},\nabla f(X^{(0)})=(-12,6)^{T}\)
可以得到\(\lambda_{0}= - \frac{\nabla f(X^{(0)})^{T}P^{(0)}}{(P^{(0)})^{T}AP^{(0)}},P^{(0)}=-\nabla f(X^{(0)})\)
然后\(X^{(1)}=X^{(0)}+\lambda_{0}P^{(0)},\beta_{0}= \frac{\nabla f(X^{(1)})^{T}\nabla f(X^{(1)})}{\nabla f(X^{(0)})^{T}\nabla f(X^{(0)})}\),继续迭代即可
注:为了掌握这种方法,建议还是多做一些练习
非二次函数的共轭梯度法¶
这种不规整的问题往往采用的都是化归方法,将复杂问题转化为我们研究过的比较简单的问题,也就是在迭代点附近做二阶的泰勒展开,就可以当作二次函数做了.
对于一般的非二次函数,共轭梯度法的计算依然适用,公式同理
一般非二次函数使共轭性遭受破坏,因而要以\(n\)步迭代取得终止常常是不可能的。所以在实际应用时,如迭代步数\(k\leqslant n\)已达到要求的精度,则以\(X(k)\)作为要求的近似解。否则可将前n步作为一个循环,同时以所得到的\(X(n)\)作为新的初始近似重新开始,进行第二个循环。重复进行,直至满足要求的精度为止。
注1:有趣的拓展,关于共轭梯度法还有许多不同的公式,例如Fletcher-Reeves公式、Dai-Yuan公式等(四个方法),四个方法可通过两个分子分母的组合得到,另一个重要的共轭梯度法PRP方法,在实际中表现比Fletcher-Reeves方法好得多.
注2:这里的拓展可以深挖,主要是不同的\(\beta_{k}\)的问题,其中的原理可以查阅相关的参考文献
牛顿法与拟牛顿法¶
拟牛顿法是近30多年来发展起来的,它是求解无约束极值问题的一种有效方法。由于它既避免了计算二阶导数矩阵及其求逆过程,又比梯度法的收敛速度快,特别是对高维问题具有显著的优越性,因而使变尺度法获得了很高的声誉,至今仍被公认为求解无约束极值问题最有效的算法之一
牛顿法原理¶
假定无约束极值问题的目标函数二阶可求偏导,\(X^{(k)}\)为其极小点的某一近似,在这个点附近取\(f(X)\)的二阶泰勒展开:
极小点满足\(\nabla f(X^{(k)})+H(X^{(k)})\Delta X=0\)
从而\(X=X^{(k)}-H(X^{(k)})^{-1}\nabla f(X^{(k)})\)
那么如果函数是二次函数,Hesse阵就是常数阵,逼近是准确的,从任意一点出发一步即可求出\(f(X)\)的极小点(假定\(H(X^{(k)})\)正定)
如果不是,那么就是近似表达式,这时就常常取\(-H(X^{(k)}\nabla f(X^{(k)}))\)为搜索方向,即
牛顿法的算法:
- 给出初始点\(x_{1}\in \mathbb{R}^{n},0\leqslant \varepsilon<1,k:=1\)
- 如果\(\lVert \nabla f(x_{k}) \rVert_{2}\leqslant \varepsilon\),停止,否则\(d_{k}=-\left[ \nabla^{2}f(x_{k}) \right]^{-1}\nabla f(x_{k})\)(Newton Step)
- 利用线搜索求\(\alpha_{k}>0\);\(x_{k+1}=x_{k}+\alpha_{k}d_{k};k=k+1\),回到2
如果\(\nabla^{2}f(x_{k})\)不正定,那么牛顿法的搜索方向可能不是下降方向,就需要修正,将牛顿法的搜索方向记为\(d_{k}^{N}\)(Newton step)
修正方法:
这样可以确保搜索方向,也就保证了算法的收敛性
但是现实是,实际问题中的目标函数过于复杂,求逆阵是困难的于是我们设法构造另一个矩阵\(\overline{H}^{(k)}\),用它来直接逼近二阶导数矩阵的逆阵\(H(X^{(k)})^{-1}\)
构造近似矩阵¶
明确一下要求是在每一步充分利用已有信息确认下一步的搜索方向,并且每做一次迭代就要使目标函数值有所下降,并且近似矩阵应当收敛于逆阵
由于二次函数时,Hesse阵为常数阵,那么在其任意两点\(X^{(k)},X^{(k+1)}\),有梯度之差为\(\nabla f(X^{(k+1)})-\nabla f(X^{(k)})=A(X^{(k+1)}-X^{(k)})\)
以下条件也被称为拟牛顿条件
简化记号为:
可以简单记为\(\Delta X^{(k)}=\overline{H}^{(k+1)}\Delta G^{(k)}\)
那么为了使\(\overline{H}^{(k+1)}\)满足拟牛顿条件,要求\(\Delta \overline{H}^{(k)}\Delta G^{(k)}=\Delta X^{(k)}-\overline{H}^{(k)}\Delta G^{(k)}\)
可以试图构造一个简单的形式,根据上式也可以进行猜想:
那么反代就可以得到\((Q^{(k)})^{T}\Delta G^{(k)}=(W^{(k)})^{T}\Delta G^{(k)}=1\)
找到对应的校正矩阵:
可以利用校正矩阵得到
拟牛顿法的计算步骤:
- 给定初始点\(X^{(0)}\)及梯度允许误差\(\varepsilon>0\)
- 若 $$ \lVert \nabla f(X^{(0)}) \rVert ^{2}\leqslant \varepsilon $$
则\(X^{(0)}\)为近似极小点,停止,否则转入3 - 令\(\overline{H}^{(0)}=I,P^{(0)}=-\overline{H}^{(0)}\nabla f(X^{(0)})\)
注1:上述方法首先由戴维顿(Davidon)提出,后经弗莱彻(Fletcher)和鲍威尔(Powell)加以改进,故称DFP法,或DFP拟牛顿法.
注2:拟牛顿法也称为变尺度(variable metric)方法.
SMW(Sherman-Morrison-Woodbury) Formula¶
高阶矩阵和低秩矩阵如何快速求解逆阵?直接对低秩的矩阵进行求逆计算就可以节约大量的计算量!
注:曾经在高等代数中遇到过并且写过习题(参考谢启鸿白皮书)
下面是另一个著名的拟牛顿法:
BFGS方法¶
它的矩阵修正公式为:
注意如果将\(B_{k}\iff H_{k},s_{k}\iff y_{k}\)对换,那么可以将DFP方法和BFGS方法相互转换(对偶性质),BFGS和DFP方法称为互为对偶方法.
Broyden利用BFGS和DFP公式构造出一族拟牛顿修正公式:
取\(\theta=0\)得到BFGS修正公式,\(\theta=1\)得到DFP修正公式
一族包含三个参数的修正公式由Huang给出形式为:
那么Broyden族是Huang族中所有对称且满足拟牛顿方程的修正公式
拟牛顿法有两个重要的性质:
不变性和二次终止性¶
- 不变性
拟牛顿法的一个重要性质是不变性(invariance),也就是经过线性变换后不变,利用这个性质分析算法时可以把\(H_{1}=1\)假设代入.
线性变换:\(\overset{\sim}{x}=Ax+a\),目标函数变为\(f(A^{-1}(\overset{\sim}{x}-a))=f(x)\)
- 二次终止性
Huang族中的任何方法在精确线搜索下具有二次终止性,在一定条件的假定下,算法必有限终止
拟牛顿法的收敛性一直以来是比较热门的研究课题,拟牛顿法收敛性研究比较成熟和完善,但仍有一些重要问题没有解决,比如DFP方法的总体收敛性问题.